

Hadoop是一个由Apache基金会所开发能够让用户轻松架构和使用的大规模数据处理平台,是处理、存储和分析海量的分布式、非结构化数据的开源框架。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,并且它的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。Hadoop具备可靠、高效、可伸缩等特点,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。有需要使用Hadoop的朋友快通过kkx分享的地址来获取吧!
Hadoop优点
1. 高可靠性。
Hadoop按位存储和处理数据的能力值得人们信赖。
2. 高扩展性。
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3. 高效性。
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4. 高容错性。
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5. 低成本。
与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop安装教程
Hadoop2.7.1的部署
机器环境:
操作系统:CentOS 6.4 64位系统
Hadoop版本:hadoop-2.7.1,在CentOS下自行编译后的64位版本。
Hadoop安装步骤
1、首先下载安装包tar zxvf hadoop-2.7.1.tar.gz
2.在虚拟机中解压安装包

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
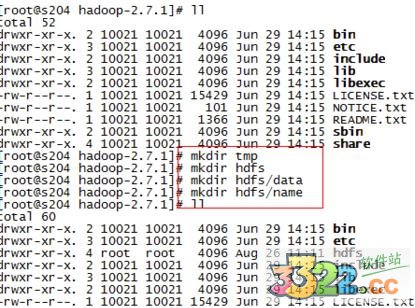
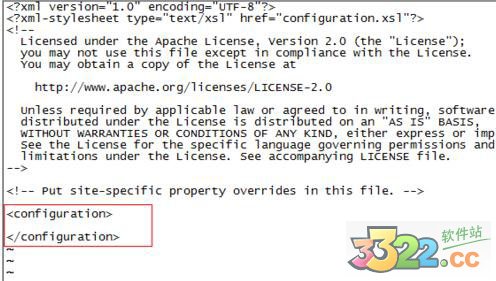
4、修改/home/yy/hadoop-2.7.1/etc/hadoop下的配置文件
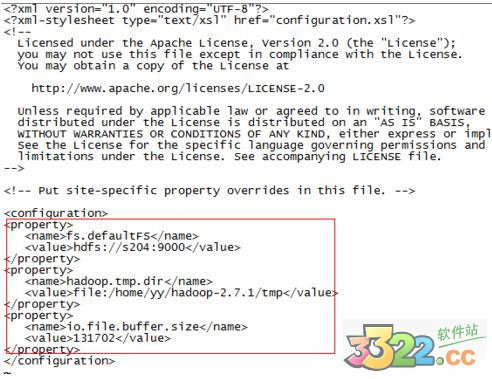
修改core-site.xml,加上
fs.defaultFS
hdfs://s204:9000
hadoop.tmp.dir
file:/home/yy/hadoop-2.7.1/tmp
io.file.buffer.size
131702
5.修改hdfs-site.xml,加上
dfs.namenode.name.dir
file:/home/yy/hadoop-2.7.1/dfs/name
dfs.datanode.data.dir
file:/home/yy/hadoop-2.7.1/dfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
s204:9001
dfs.webhdfs.enabled
true

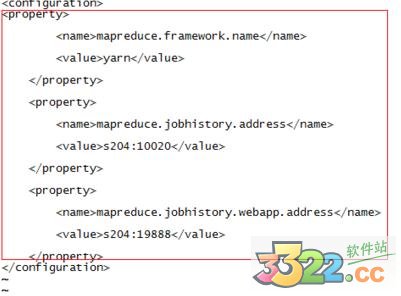
6.修改mapred-site.xml,加上
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
s204:10020
mapreduce.jobhistory.webapp.address
s204:19888
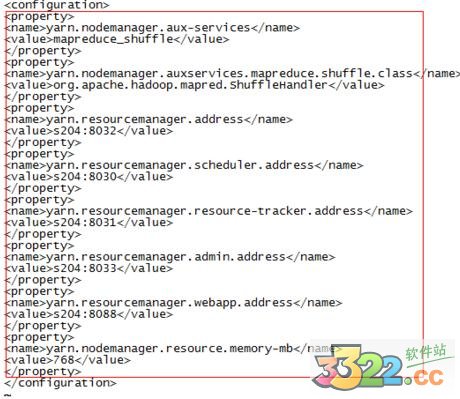
7.修改yarn-site.xml,加上
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
s204:8032
yarn.resourcemanager.scheduler.address
s204:8030
yarn.resourcemanager.resource-tracker.address
s204:8031
yarn.resourcemanager.admin.address
s204:8033
yarn.resourcemanager.webapp.address
s204:8088
yarn.nodemanager.resource.memory-mb
768
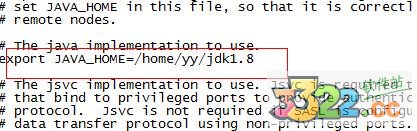
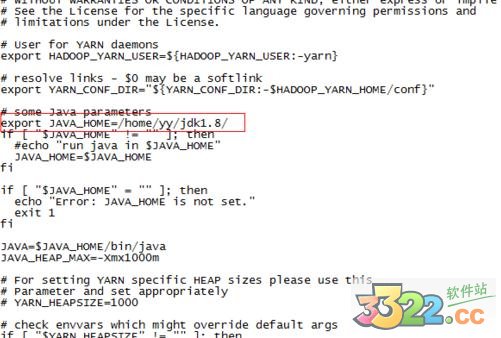
8、配置/home/yy/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/home/yy/jdk1.8
9.配置/home/yy/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,我这里只有一个s205
配置成功后,将hadhoop复制到各个从服务器上
scp -r /home/yy/hadoop-2.7.1 root@s205:/home/yy/

10.主服务器上执行bin/hdfs namenode -format
进行初始化
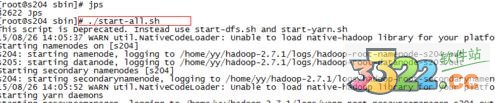
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.这时可以浏览器打开s204:8088查看集群信息啦
到此配置完成,如图:
优势
Hadoop是一个基本框架,容许用简单的编程实体模型在计算机中集群中对大中型数据开展分布式解决。它设计规模从单一网络服务器到数千台设备,每一个网络服务器都可以提供当地运算存放作用,框架自身提供是指电子计算机集群高可用性服务,不依赖硬件配置来提供可扩展性。用户可在不太了解分布式最底层关键点的情形下,快速地在Hadoop上开发与运作解决大数据的应用软件。降低成本、高可靠、高拓展、高合理、高容错机制等特点让hadoop变成最流行大数据分析平台。
Hadoop的生态系统,主要是由HDFS、MapReduce,HBase,Zookeeper,Pig、Hive等关键部件组成,同时还包含Sqoop、Flume等框架,用于与其他公司系统融合。与此同时,Hadoop生态系统还在不断增加,它增加了Mdhout、Ambari等相关信息,以提供升级作用。
软件截图

猜你喜欢
- 查看详情 MinGW离线安装版42MB多国语言2024-05-16
- 查看详情 VS2017官方下载(Visual Studio 2017)14.9GB多国语言2024-05-16
- 查看详情 MyDiskTestU盘扩容检测工具官方下载7.15MB多国语言2024-05-16
- 查看详情 ZBrush免费版下载1.07GB多国语言2024-05-16
Hadoop V2.7.1免费版这么好的软件你到哪里去找啊
安装完的朋友能不能说一下Hadoop V2.7.1免费版能不能选择安装路径呢。
很好,Hadoop V2.7.1免费版2.0已安装并使用了,谢谢!
太好了
各位要是想要功能更强大的Hadoop V2.7.1免费版,就请换共享软件的版本吧
找了那么久,终于找到了,必须点赞。
taob淘宝网软件帮我了很大忙,感谢du114
在我用过的网络辅助软件里,这个Hadoop V2.7.1免费版算不上是最稳定,最快的,但绝对是最特别的。
以前这个Hadoop V2.7.1免费版大小很小,现在居然都已经0.3MB了
呵呵,没想到Hadoop V2.7.1免费版还会有这么多人喷,你们会用么?自己笨还怨软件不行,多学习学习再来吧。































